This
article
has been
re-written with the help of 2 years of
feedback, and the new
source code
has benefited
from all of the fixes and developments
during that time period. See
release notes below.
Introduction
Often times
you don't want to invest in learning a
complex XML tool
to implement a little bit of
XML processing
in your application. Its SO Easy! Just add
Markup.cpp and Markup.h to
your Visual C++ MFC
project,
#include
"Markup.h",
and begin using it. There are no other
dependencies.
Features
- Light:
one small class that maintains one
single document string with a simple
array of indexes
- Fast:
the parser builds the index array in one
quick pass
-
Simple: EDOM methods make it
ridiculously easy to
create
or process XML
strings
-
Independent: compiles into your program
without requiring
MSXML or any tokenizer
-
UNICODE: can be compiled for UNICODE for
Windows CE and NT/XP platforms (define
_UNICODE)
- UTF-8:
when not in UNICODE or MBCS builds, it
works with UTF-8, ASCII, or Windows
extended sets
-
MBCS: can be compiled for Windows
double-byte character sets such as
Chinese GB2312 (define
_MBCS)
XML for
Everyday Data
We often
need to store
and/or pass information in a
file, or
send a block of information from computer A
to computer B. And the issue is always the
same: How shall I format this data?
Before XML,
you might have considered "env" style e.g.
PATH=C:\WIN95; "ini" style (grouped in
sections); comma-delimited or otherwise
delimited; or fixed character lengths.
XML is
now the established answer to that question
except that programmers are sometimes
discouraged by the size and complexity of
XML
solutions when all they need is something
convenient to help parse and format angle
brackets. For good minimalist reading on the
syntax rules for
XML tags, I recommend Beginning
XML - Chapter 2: Well-Formed
XML
posted here.
XML is
better because of its flexible and
hierarchical nature, plus its wide
acceptance. Although
XML uses more characters than
delimited formats, it compresses down well
if needed. The flexibility of
XML
becomes apparent when you want to expand the
types of information your document can
contain without requiring every consumer of
the information to rewrite processing logic.
You can keep the old information identified
and ordered the same way it was while adding
new attributes and elements.
CMarkup
Lite Methods
CMarkup
is based on the "Encapsulated" Document
Object Model (EDOM), the key to
simple XML
processing. Its a set of methods for
XML
processing with the same general purpose as
DOM (Document Object Model). But while
DOM has
numerous types of objects, EDOM defines only
one object, the XML
document. EDOM harks back to the
original attraction of
XML which was its simplicity.
To keep overhead low,
CMarkup
takes a very light non-conforming
non-validating approach to
XML, and
it does not verify the
XML is well-formed.
The
CMarkup "Lite"
in this article
is the free version of the
CMarkup
product sold at firstobject.
CMarkup
Lite implements a subset of EDOM methods for
creating and parsing
XML document strings. The Lite
methods also encompass some modification
functionality such as setting an attribute
or adding additional elements to an existing
XML document,
but not changing the data of, or removing,
XML elements.
See the EDOM specification to compare the
full
CMarkup
with
CMarkup
Lite. The full
CMarkup
is available in Evaluation (Educational) and
licensed Developer versions with many more
methods, STL and MSXML versions, Base64, and
additional documentation. But this Lite
version here is more than adequate for
parsing and creating simple
XML
strings in MFC.
The
CMarkup
Lite methods are grouped into Creation and
Navigation categories listed below.
CMarkup
Lite Creation Methods
CString GetDoc() const { return m_csDoc; };
bool AddElem( LPCTSTR szName, LPCTSTR szData=NULL );
bool AddChildElem( LPCTSTR szName, LPCTSTR szData=NULL );
bool AddAttrib( LPCTSTR szAttrib, LPCTSTR szValue );
bool AddChildAttrib( LPCTSTR szAttrib, LPCTSTR szValue );
bool SetAttrib( LPCTSTR szAttrib, LPCTSTR szValue );
bool SetChildAttrib( LPCTSTR szAttrib, LPCTSTR szValue );
GetDoc
is used to get the document string after
adding elements and setting attributes. The
AddAttrib
and
SetAttrib
methods do the same thing as each other (as
do
AddChildAttrib
and
SetChildAttrib).
They will change the attribute's value if it
already exists, and add the attribute if it
doesn't.
CMarkup
Lite Navigation Methods
bool SetDoc( LPCTSTR szDoc );
bool IsWellFormed();
bool FindElem( LPCTSTR szName=NULL );
bool FindChildElem( LPCTSTR szName=NULL );
bool IntoElem();
bool OutOfElem();
void ResetChildPos();
void ResetMainPos();
void ResetPos();
CString GetTagName() const;
CString GetChildTagName() const;
CString GetData() const;
CString GetChildData() const;
CString GetAttrib( LPCTSTR szAttrib ) const;
CString GetChildAttrib( LPCTSTR szAttrib ) const;
CString GetError() const;
When you
call
SetDoc
it parses the
szDoc
string and populates the
CMarkup
object. If it fails, it returns
false,
and you can call
GetError
for an error description. The
IsWellFormed
method returns
true
if the
CMarkup
object has at least a root element; it does
not verify well-formedness.
Using
CMarkup
The
CMarkup
class encapsulates the
XML document text, structure,
and current positions. It has methods both
to add elements and to navigate and get
element attributes and data. The locations
in the document where operations are
performed are governed by the current
position and the current child position.
This current positioning allows you to work
with the XML
document without instantiating
additional objects that point into the
document. At all times, the object maintains
a string representing the text of the
document
which can be retrieved using
GetDoc.
Check out
the free firstobject
XML editor which generates
C++ source code
for creating and navigating your own
XML documents
with
CMarkup
Lite.
Creating an
XML Document
To
create
an XML document,
instantiate a
CMarkup
object and call
AddElem
to create the root element. At this point,
if you called
AddElem("ORDER")
your document would simply contain the empty
ORDER element
<ORDER/>.
Then call
AddChildElem
to create elements under the root element
(i.e. "inside" the root element,
hierarchically speaking). The following
example code creates an XML document and
retrieves it into a
CString:
CMarkup xml;
xml.AddElem( "ORDER" );
xml.AddChildElem( "ITEM" );
xml.IntoElem();
xml.AddChildElem( "SN", "132487A-J" );
xml.AddChildElem( "NAME", "crank casing" );
xml.AddChildElem( "QTY", "1" );
CString csXML = xml.GetDoc();
This code
generates
the following XML.
The root is the ORDER element; notice that
its start tag
<ORDER>
is at the beginning and end tag
</ORDER>
is at the bottom. When an element is under
(i.e. inside or contained by) a parent
element, the parent's start tag is before it
and the parent's end tag is after it. The
ORDER element contains one ITEM element.
That ITEM element contains 3 child elements:
SN, NAME, and QTY.
<ORDER>
<ITEM>
<SN>132487A-J</SN>
<NAME>crank casing</NAME>
<QTY>1</QTY>
</ITEM>
</ORDER>
As shown in
the example, you can create elements under a
child element by calling
IntoElem
to move your current main position to where
the current child position is so you can
begin adding under what was the child
element.
CMarkup
maintains a current position in order to
keep your source code shorter and simpler.
This same position logic is used when
navigating a document.
Navigating
an XML Document
The
XML
string created in the above
example
can be parsed into a
CMarkup
object with the
SetDoc
method. You can also navigate it right
inside the same
CMarkup
object where it was created; just call
ResetPos
if you want to reset the current position
back to the beginning of the document.
In the
following example, after populating the
CMarkup
object from the
csDoc
string, we loop through all ITEM elements
under the ORDER element and get the serial
number and quantity of each item:
CMarkup xml;
xml.SetDoc( csXML );
while ( xml.FindChildElem("ITEM") )
{
xml.IntoElem();
xml.FindChildElem( "SN" );
CString csSN = xml.GetChildData();
xml.FindChildElem( "QTY" );
int nQty = atoi( xml.GetChildData() );
xml.OutOfElem();
}
For each
item we find, we call
IntoElem
before interrogating its child elements, and
then
OutOfElem
afterwards. As you get accustomed to this
type of navigation you will know to check in
your loops to make sure there is a
corresponding
OutOfElem
call for every
IntoElem
call.
Adding
Elements and Attributes
The above
example for creating a document only created
one ITEM element. Here is an example that
creates multiple items loaded from a
previously populated data source, plus a
SHIPMENT information element in which one of
the elements has an attribute. This code
also demonstrates that instead of calling
AddChildElem,
you can call
IntoElem
and
AddElem.
It means more calls, but some people find
this more intuitive.
CMarkup xml;
xml.AddElem( "ORDER" );
xml.IntoElem(); for ( int nItem=0; nItem<aItems.GetSize(); ++nItem )
{
xml.AddElem( "ITEM" );
xml.IntoElem(); xml.AddElem( "SN", aItems[nItem].csSN );
xml.AddElem( "NAME", aItems[nItem].csName );
xml.AddElem( "QTY", aItems[nItem].nQty );
xml.OutOfElem(); }
xml.AddElem( "SHIPMENT" );
xml.IntoElem(); xml.AddElem( "POC" );
xml.SetAttrib( "type", csPOCType );
xml.IntoElem(); xml.AddElem( "NAME", csPOCName );
xml.AddElem( "TEL", csPOCTel );
This code
generates the following
XML. The
root ORDER element contains 2 ITEM elements
and a SHIPMENT element. The ITEM elements
both contain SN, NAME and QTY elements. The
SHIPMENT element contains a POC element
which has a type attribute, and NAME and TEL
child elements.
<ORDER>
<ITEM>
<SN>132487A-J</SN>
<NAME>crank casing</NAME>
<QTY>1</QTY>
</ITEM>
<ITEM>
<SN>4238764-A</SN>
<NAME>bearing</NAME>
<QTY>15</QTY>
</ITEM>
<SHIPMENT>
<POC type="non-emergency">
<NAME>John Smith</NAME>
<TEL>555-1234</TEL>
</POC>
</SHIPMENT>
</ORDER>
Finding
Elements
The
FindElem
and
FindChildElem
methods go to the next sibling
element. If the optional tag name argument
is specified, then they go to the next
element with a matching tag name. The
element that is found becomes the current
element, and the next call to Find will go
to the next sibling or matching sibling
after that current position.
When you
cannot assume the order of the elements, you
must reset the position in between calling
the Find method. Looking at the ITEM element
in the above example, if someone else is
creating the XML
and you cannot assume the SN element is
before the QTY element, then call
ResetChildPos()
before finding the QTY element.
To find the
item with a particular serial number, you
can loop through the ITEM elements and
compare the SN element data to the serial
number you are searching for. This example
differs from the original navigation example
by calling
IntoElem
to go into the ORDER element and use
FindElem("ITEM")
instead of
FindChildElem("ITEM");
either way is fine. And notice that by
specifying the "ITEM" element tag name in
the Find method we ignore all other sibling
elements such as the SHIPMENT element.
CMarkup xml;
xml.SetDoc( csXML );
xml.FindElem(); xml.IntoElem(); while ( xml.FindElem("ITEM") )
{
xml.FindChildElem( "SN" );
if ( xml.GetChildData() == csFindSN )
break; }
Encodings
ASCII
refers to the character codes under 128 that
we have come to depend on, programming in
English. Conveniently if you are only using
ASCII, UTF-8 encoding is the same as your
common ASCII set.
If you are
using a character set not corresponding to
one of the Unicode sets UTF-8, UTF-16 or
UCS-2, you really should declare it in your
XML declaration for the sake of
interoperability and viewing it properly in
Internet Explorer. Character sets like
ISO-8859-1 (Western European) assign
characters to the values in a byte between
128 and 255, so that every character still
only uses one byte. Windows double-byte
character sets such as GB2312, Shift_JIS and
EUC-KR use one or two bytes per character.
For these Windows charsets, put
_MBCS
in your preprocessor definitions and make
sure your user's Operating System is set to
the corresponding code page.
To prefix
your XML document
with an XML
declaration such as
="1.0"
="ISO-8859-1",
pass it to
SetDoc
or the
CMarkup
constructor. Include a CRLF at the end as
shown so that the root element goes on the
next line.
xml.SetDoc( "<?xml version=\"1.0\" encoding=\"ISO-8859-1\"?>\r\n" );
xml.AddElem( "island", "Curaçao" );
Depth
First Traversal
You can use
the following code to loop through every
element in your XML document. In the
part of the code where you process the
element, every element in the document
(except the root element) will be
encountered in depth first order. For
illustrative purposes, it gets the tag name
of the element. If you were searching for a
particular element tag name you could break
out of the loop at this point. "Depth first"
means that it traverses all of an element's
children before going to its sibling.
BOOL bFinished = FALSE;
xml.ResetPos();
if ( ! xml.FindChildElem() )
bFinished = TRUE;
while ( ! bFinished )
{
xml.IntoElem();
CString csTag = xml.GetTagName();
BOOL bFound = xml.FindChildElem();
while ( ! bFound && ! bFinished )
{
if ( xml.OutOfElem() )
bFound = xml.FindChildElem();
else
bFinished = TRUE;
}
}
Loading and
Saving Files
CMarkup
Lite does not have
Load
and
Save
methods. To load
a file,
look in the
CMarkupDlg::OnButtonParse
method which loads a file into a string.
Once you have it in a string, you can put it
into the
CMarkup
object using
SetDoc.
To save it to a file, call
GetDoc
to get the string and then implement your
own code to write the string to your file.
When you need to implement any of your own
project specific I/O error handling,
streaming, permissions/locking, and charset
conversion, it is actually good software
design to keep this outside of the
CMarkup
class allowing
CMarkup
to remain a generic class.
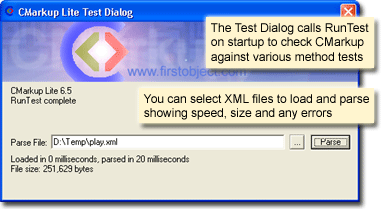
The Test
Dialog
The
Markup.exe test bed for
CMarkup
is a Visual Studio 6.0 MFC project (also
compiles in VS .NET too). When the dialog
starts, it performs diagnostics in the
RunTest
function to test
CMarkup
in the context of the particular build
options that have been selected. You can
step through the
RunTest
function to see a lot of examples of how to
use
CMarkup.
Use the Open and Parse button in the dialog
to test a file.
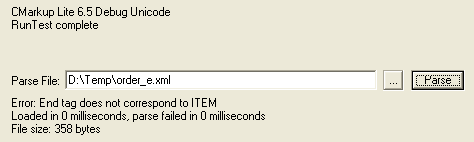
In the
following illustration, the Build Version is
shown as "CMarkup Lite 6.5 Debug Unicode."
This means that it is the debug version
built with
_UNICODE
defined. The
RunTest
completed successfully. A parse error was
encountered in the order_e.xml file.
It also shows the load and parse times, and
file size.
The Test
Dialog keeps track of the last file parsed
and the dialog screen position for
convenience. This is kept in the registry
under HKEY_CURRENT_USER/ Software/ First
Objective Software/ Markup/ Settings.
How
CMarkup Works
The CMarkup
strategy is to leave the data in the
document string and maintain a hierarchical
arrangement of indexes mapping out the
document.
-
increase speed: parse in one pass
and maintain hierarchy of indexes
-
reduce overhead: do not copy or
break up the text of the document
CMarkup
parses the 250k play.xml sample
document in about 40 milliseconds (1/25th of
a second) on a 500Mhz machine, holding it as
a single string, and allocating about 200k
for a map of the 6343 elements. From then
on, navigation does not require any parsing.
As a rule of thumb, the map of indexes takes
up approximately the same amount of memory
as the document, so the memory footprint of
the
CMarkup
object should settle down around 2 times the
size of the document. For each element in
the document a struct of eight integers (32
bytes) is maintained.
int nStartL;
int nStartR;
int nEndL;
int nEndR;
int nReserved;
int iElemParent;
int iElemChild;
int iElemNext;
Look at the
start and end tags in
<QTY>1</QTY>.
The struct contains the offsets of the left
and right of both the start and end tags
(i.e. all the < and > signs). The reserved
integer is not currently used but could be
used for a delete flag and/or level (i.e.
depth) in the hierarchy to support
indentation. The other three integers are
indexes to the structs for the parent, child
and next elements.
When the
document is first parsed an array of these
structs is built, and then as elements are
modified and inserted in the
XML, the
structs are modified and added. Rather than
allocating structs individually, they are
allocated in an array using a "grow-by"
mechanism to reduce the number of
allocations to a handful. That is why
integer array indexes rather than pointers
are used for the links. Once an element is
assigned an index in the array, that index
does not change. So the index can be used as
a way of referring to and locating an
element
Release
Notes
This
release 6.5 of
CMarkup
Lite's public methods are backwards
compatible with the previous release 6.1
posted here in August 2001 except for one
rare usage of
IntoElem.
In 6.1, if you called
IntoElem
without a current child element, it would
find the first child element. Now in 6.5
when there is no current child position,
IntoElem
puts the main position before the first
child element so that a subsequent call to
FindElem
will not bypass the first element. So, the
quick way to check this when upgrading is to
scan all occurrences of
IntoElem
and make sure the previous CMarkup
navigation call is
FindChildElem
before it. Or, if the child element was just
created with
AddChildElem
then its okay because that sets the current
child position too. For full details on
this, see the IntoElem Changes in Release
6.3.
Other major
changes since 6.1:
-
Fix:
MBCS double-byte text
x_TextToDoc
*thanks knight_zhuge
-
Performance: parsing is roughly twice as
fast
-
Debugging: see
m_pMainDS
and
m_pChildDS
class members while debugging to see
string pointers showing current main and
child positions
- New
Test Dialog interface with diagnostic
results and load vs. parse times, and
RunTest
code for startup
License
CMarkup
Lite is free for compiling into your
commercial, personal and educational
applications. Modify it as much as you like,
but retain the copyright notice in the
source code remarks. Redistribution of the
modified or unmodified
CMarkup
Lite class source code is limited to your
own development team and it cannot be made
publicly available or distributable as part
of any source code library or product, even
if that offering is free. For source code
products that derive from or utilize
CMarkup
Lite, please refer users to this article to
obtain the source files for themselves. You
are encouraged to discuss this source code
and share enhancements here in the
discussion board under this article. Enjoy!


